Enabling OpenVINO Inference in Podman AI Lab

Introduction to Podman AI Lab
Podman AI Lab is an open-source platform designed to simplify the deployment, management, and experimentation of AI workloads using container technology. It provides a user-friendly interface for running, testing, and scaling AI models locally or in the cloud, leveraging the power and flexibility of Podman containers.
What is OpenVINO?
OpenVINO™ (Open Visual Inference and Neural Network Optimization) is an open-source toolkit developed by Intel to accelerate AI inference on a variety of hardware, including CPUs, GPUs, and specialized accelerators. It optimizes deep learning models for fast, efficient inference, making it a popular choice for edge and cloud AI applications.
Using OpenVINO in Podman AI Lab
Podman AI Lab now supports OpenVINO as an inference provider. This means you can:
- Select an OpenVINO compatible model when starting an inference server or playground.
- Benefit from hardware-accelerated inference on supported Intel devices.
- Easily switch between different inference providers (e.g., llama-cpp, OpenVINO) for benchmarking and compatibility testing.
This feature is only available on Intel based systems, as OpenVINO is optimized for Intel hardware. If you are using a non-Intel system, you will not be able to use OpenVINO as an inference provider.
How to use:
- Launch Podman AI Lab and navigate to the model deployment or playground section.
- When configuring your model, choose an OpenVINO compatible model.
- Start the inference server or playground.
Starting an OpenVINO inference server
- Click the Podman AI Lab icon in the navigation bar.
- In the Podman AI Lab navigation bar, click Models > Services menu item.
- Click the New Model Service button on the top right.
- Select an OpenVINO compatible model in the list (e.g. OpenVINO/mistral-7B-instruct-v0.2-int4-ov) in the Model list and click the Create Service button.
- The inference server for the model is being started and after a while, click on the Open service details button.
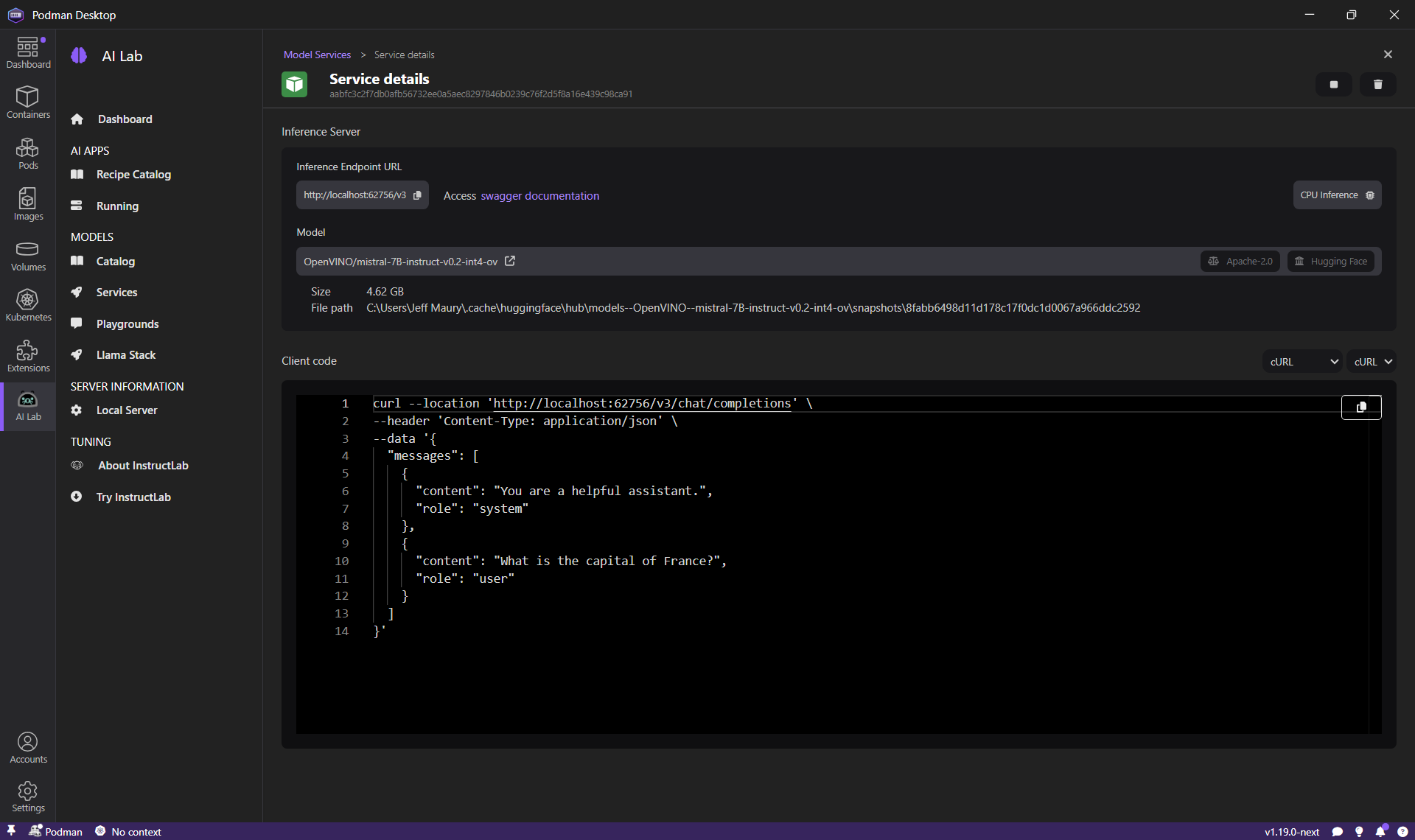
Using the terminal shell, execute the given curl command and see the inference result output.
Starting a playground with an OpenVINO compatible model
- Click the Podman AI Lab icon in the navigation bar.
- In the Podman AI Lab navigation bar, click Models > Playgrounds menu item.
- Click the New Playground button on the top right.
- Select an OpenVINO compatible model in the list (e.g. OpenVINO/mistral-7B-instruct-v0.2-int4-ov) in the Model list and click the Create playground button.
- The playground for the model is being started and after a while, a chat interface is displayed.
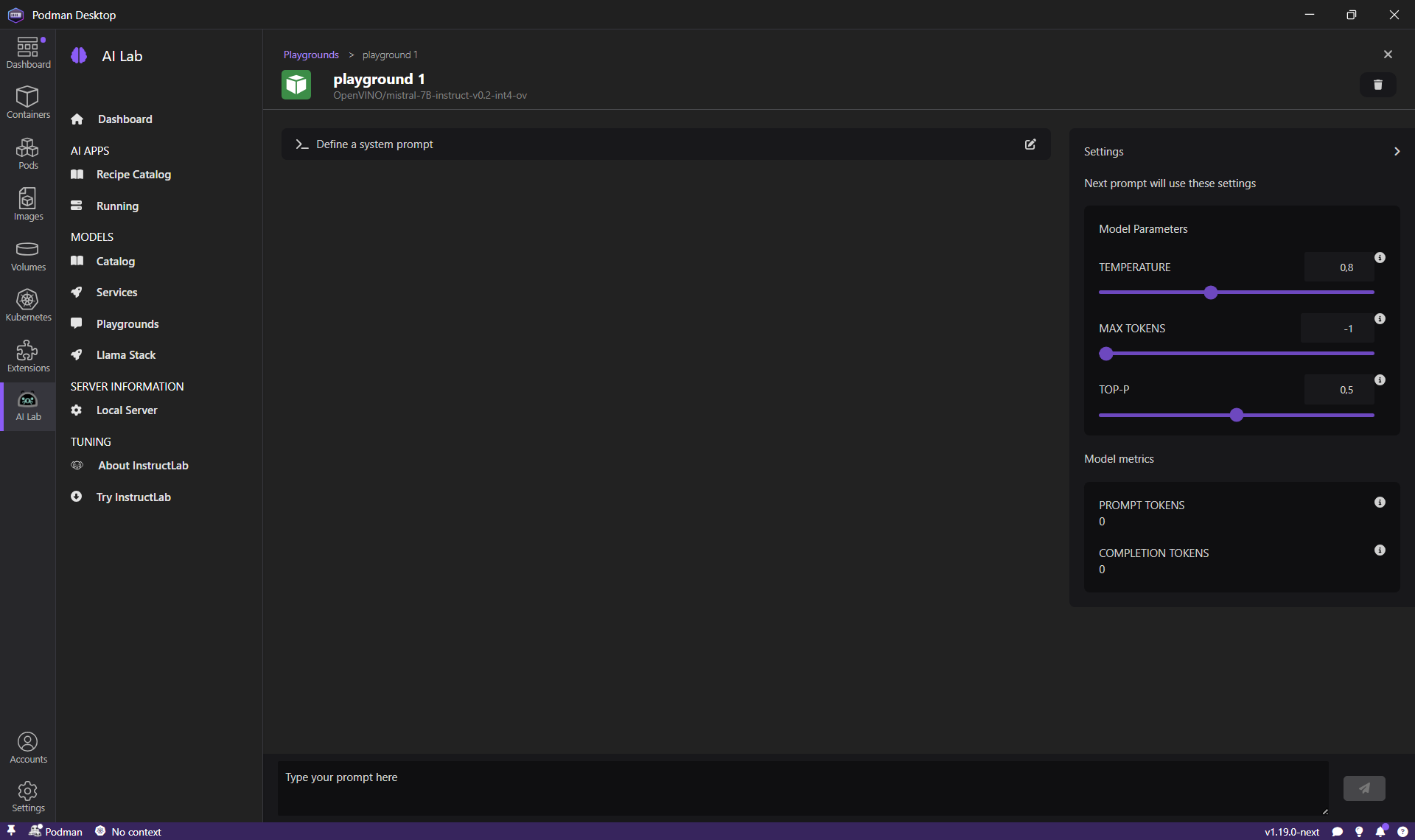
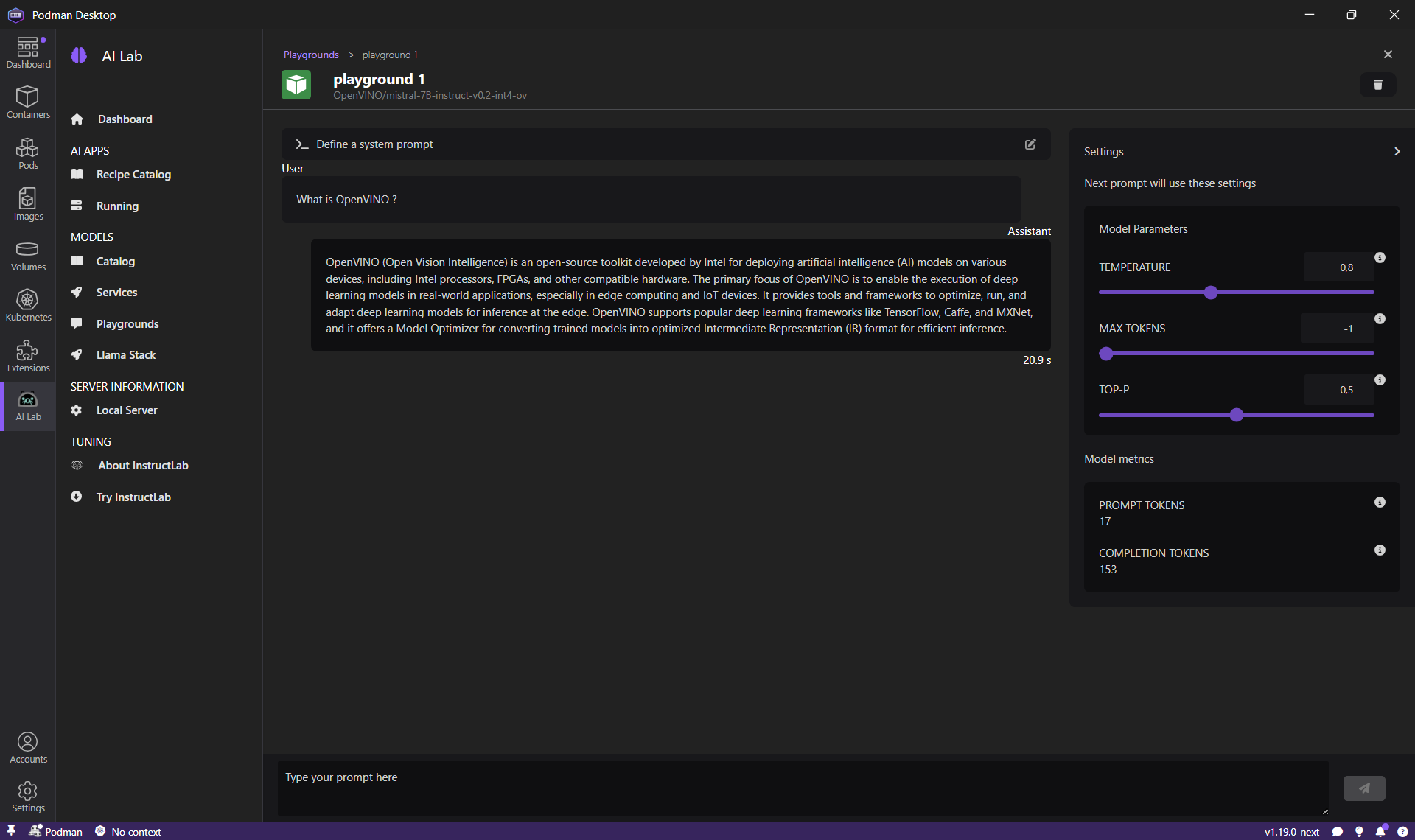
Enter 'What is OpenVINO?' in the prompt and click the Send button. The OpenVINO model will respond with an answer.
Consistency with OpenShift AI + OpenVINO
One of the key advantages of using OpenVINO in Podman AI Lab is the consistency it brings when transitioning workloads to OpenShift AI. Both platforms now support OpenVINO, ensuring that:
- Models tested and optimized locally in Podman AI Lab will behave the same way when deployed to OpenShift AI.
- You can maintain a unified workflow from development to production, reducing surprises and integration issues.
- Performance optimizations and hardware acceleration are preserved across environments.
Conclusion
By enabling OpenVINO as an inference provider, Podman AI Lab empowers users to leverage high-performance AI inference both locally and in the cloud, with a consistent experience across platforms like OpenShift AI. This integration streamlines the AI development lifecycle and unlocks new possibilities for deploying efficient, scalable AI solutions.