Starting an inference server for a model
Once a model is downloaded, a model service can be started. A model service is an inference server that runs in a container and exposes the model through the well-known chat API common to many providers.
Prerequisites
Procedure
-
Click the Podman AI Lab icon in the left navigation pane.
-
In the Podman AI Lab navigation bar, click Services.
-
Click the New Model Service button at the top right corner of the page. The Creating Model service page opens.
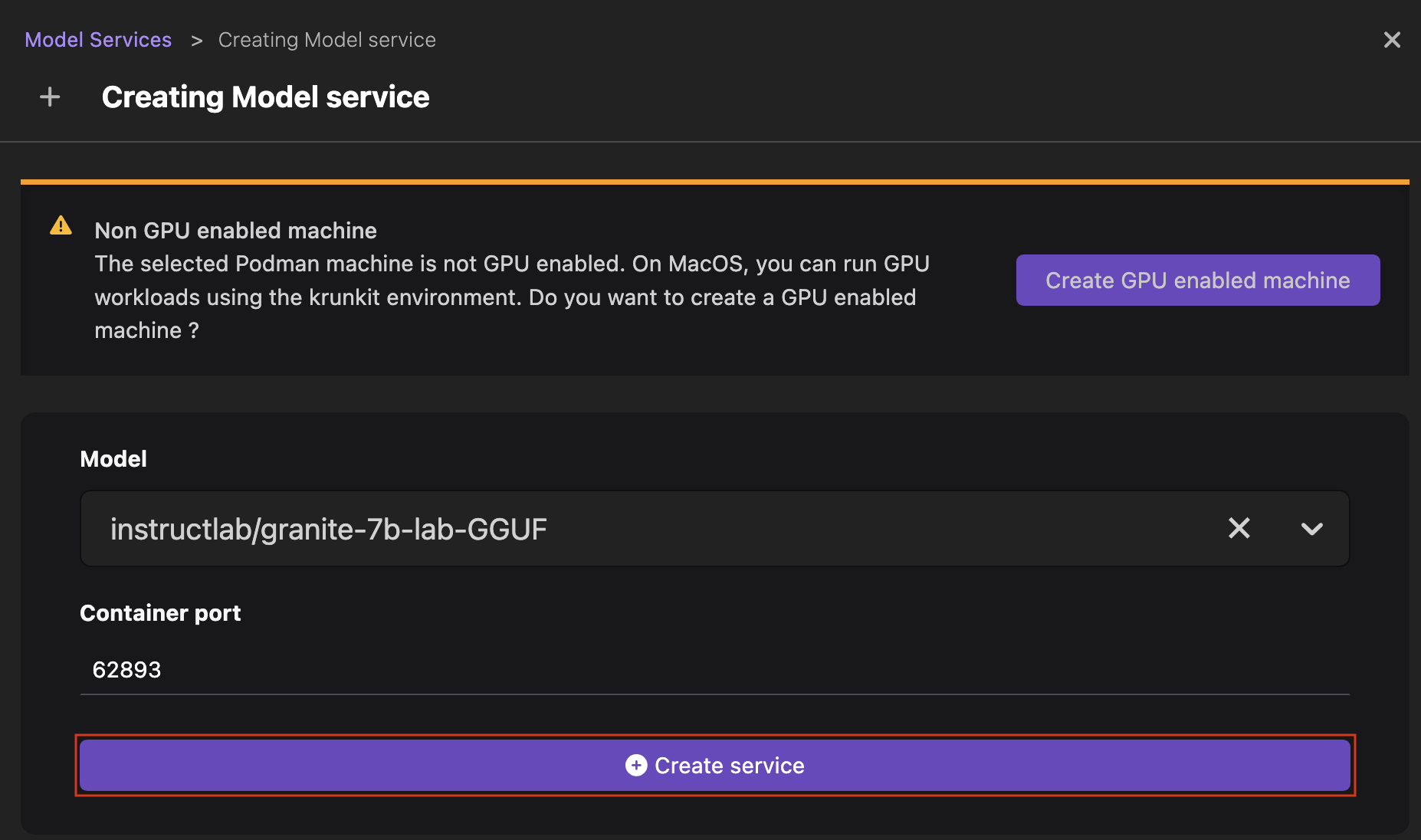
noteOn a macOS machine, you get a notification to create a GPU-enabled Podman machine to run your GPU workloads. Click the Create GPU enabled machine button to proceed.
-
Select the model for which you want to start an inference server from the dropdown list, and edit the port number if needed.
-
Click Create service. The inference server for the model is being started, and this requires some time.
-
Click the Open service details button.
Verification
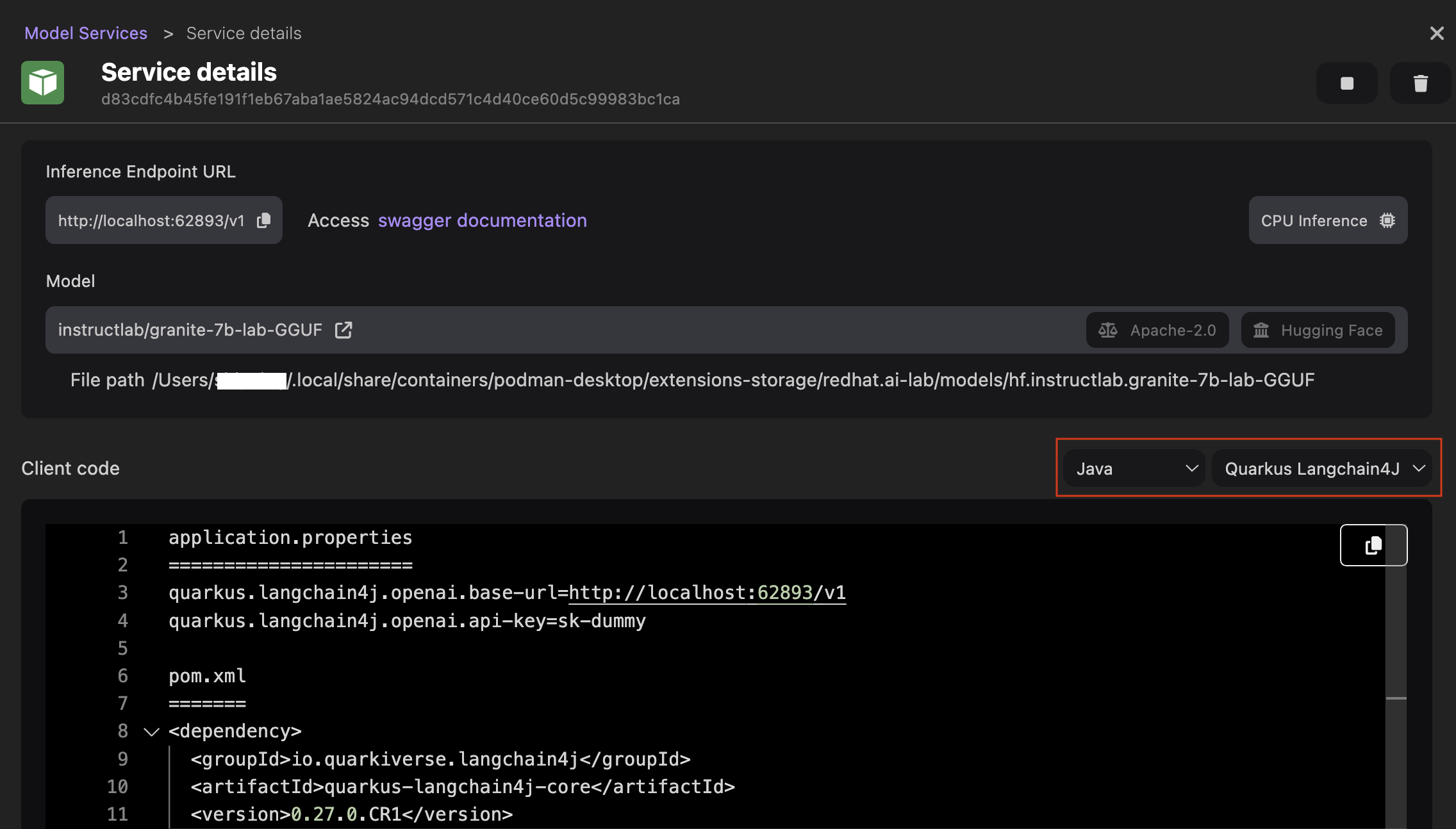
- View the details of the inference server.
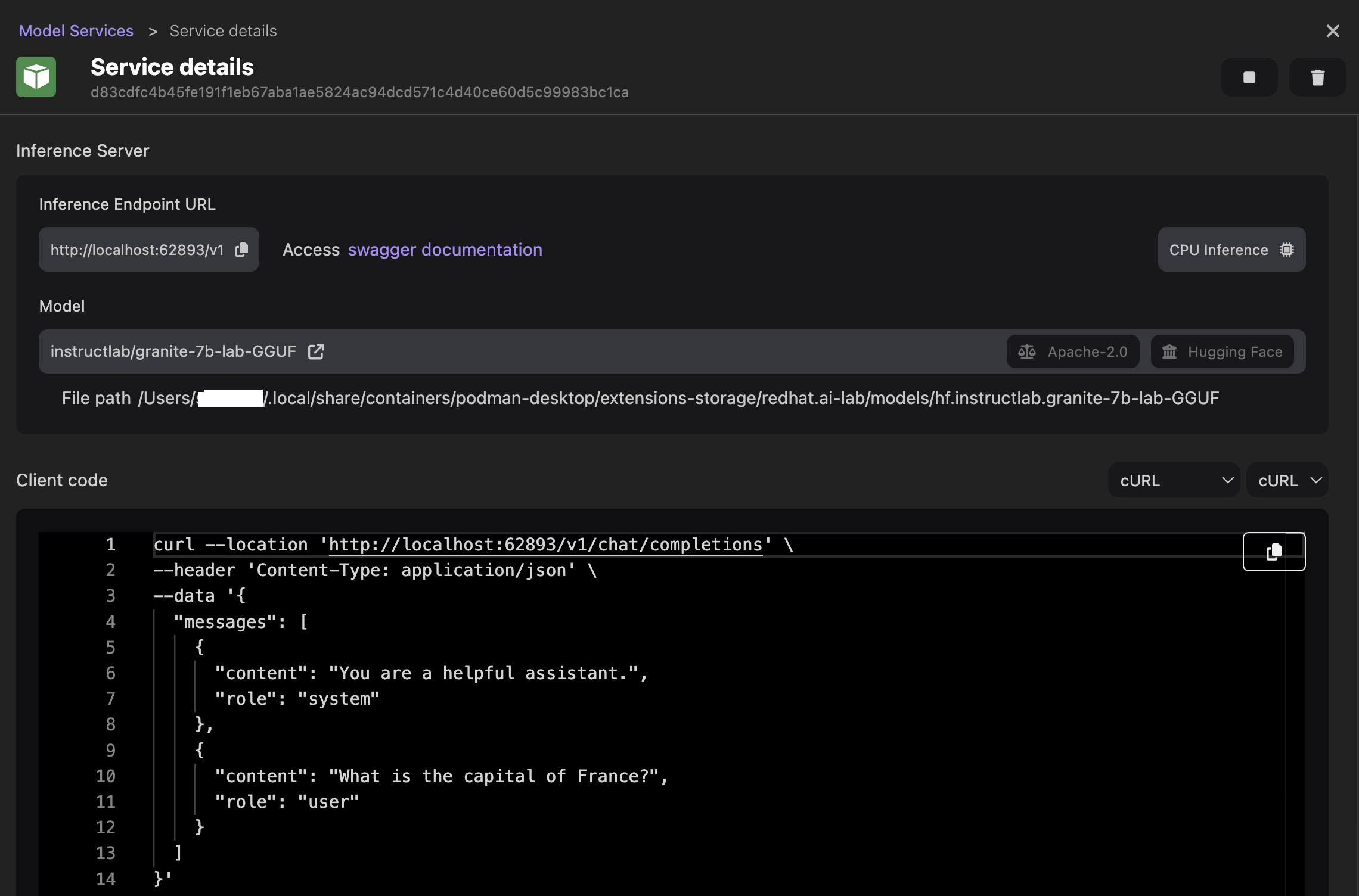
- Optional: Customize the client code based on your programming language to access the model through the inference server. For example, set the code language to
JavaandQuarkus Langchain4J, and view the updated code snippet.